DANSA: Statistical models to relate speech gestures to meaning
Overview
DANSA (dynamic analysis of speech articulation) was a three-year EPSRC-funded research project, from January 2005 to December 2007, that aimed to model the properties of speech dynamics that correspond to real articulatory gestures, and to incorporate the models into an automatic speech recognition (ASR) system.
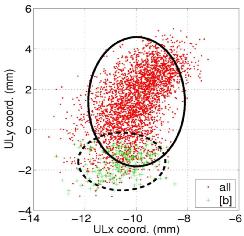
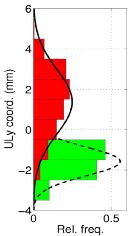
Figure 1. Articulatory data for upper lip: (left) scatter, (right) distributions. The human vocal apparatus provides major constraints on the speech sounds that can be produced, which change over the course of an utterance, as shown for the labial stop consonant [b] in Fig. 1. Properly represented, these constraints offer the potential of substantial improvements in ASR performance under the most challenging conditions: for continuous speech recognition in noisy environments. In contrast to earlier work that concentrated on linear mappings between pseudo-articulatory (formant) and acoustic representations, this project focused on understanding what characteristics of articulatory movements are important for recognition, and how they might be captured in a generic yet parsimonious model.
Learning model parameters from speech data was central to our approach to provide accurate descriptions of gestures made by the articulators: lips, jaw, tongue, velum and larynx. Statistical and probabilistic techniques were used, including maximum likelihood (ML) estimation, training by expectation maximisation (EM), and rigorous evaluation on unseen test data. By extending these techniques to learn models of articulatory motion, we seek not only to achieve improvements in recognition accuracy but also to obtain a realistic and useful representation of the way fluent speech is produced.
More...
Selected publications
[ slides ] PJB Jackson ,V Singampalli ,Y Shiga ,M Russell (2009 ). "Articulatory targets in speech ".Invited talk ,UEA, Norwich, UK .
[ bib | doi | preprint ] PJB Jackson ,V Singampalli (2009 ). "Statistical identification of critical articulators in the production of speech ".Speech Communication ,51 (8) ,695-710 .
PJB Jackson ,V Singampalli (2008 ). "Coarticulatory constraints determined by automatic identification from articulograph data ". InProc. 8th International Seminar on Speech Production (ISSP'08), p.377-380 ,Strasbourg, France . [ bib | preprint | poster ]
[ bib | doi | preprint ] Y Shiga ,PJB Jackson (2008 ). "Start-node and end-node pruning for efficient segmental-HMM decoding ".Electronics Letters ,40 (1) ,60-61 .
[ bib | preprint | slides ] V Singampalli ,PJB Jackson (2007 ). "Statistical identification of critical, dependent and redundant articulators ". InProc. Interspeech 2007 ,70-73 ,Antwerp, Belgium .
Funded in the UK by EPSRC (GR/S85511/01).