DANSA research
Speech articulation
Rather than watching, listening or prodding, we believe that the best way to study how a person speaks is directly from measurements of their speech articulation. Using electro-magnetic articulograph (EMA) recordings of fleshpoints on the speaker's mid-sagittal plane from the MOCHA-TIMIT database [Wrench01], as in Fig. 2, we considered how to determine the gestures that combine into fluid speech movement. How is an utterance choreographed?
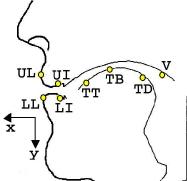
Fig. 2: EMA coil positions.
To begin, we gathered samples from the middle of each realised phoneme, or phone. By examining the statistics of these collections of samples, we could clearly see different patterns of individual speech sounds. An example of the velar stop consonant [g] is shown in Fig. 3. Comparing statistically the observed articulator distributions to the overall average, we were able to determine automatically from the data which articulators were required for that phone (for [g], it was the tongue dorsum TD).
![Phone [g]](phone_g.jpg)
Fig. 3: Vocal tract outline for phone [g] (green, dash-dot) sketched from fleshpoint distributions (represented by ellipses), against the overall average (grand, solid black).
Segmental models for ASR
Segmental hidden Markov models (HMMs) provide the probabilistic basis for comparing different potential recognition hypotheses for a given utterance. A segmental HMM generates a sequence of probability density functions (pdfs). In Fig. 4, one hypothesis enters state i at time (t-D+1) and leaves at time t, producing D=3 pdfs in the observation domain along a linear trajectory (blue line).
As with most ASR systems, the observations are acoustic features extracted from the microphone signal. However, we employ a multi-layer segmental HMM, developed in the Balthasar project, which forms trajectories in an intermediate layer that are then mapped onto the acoustic domain. Here, the intermediate layer corresponds to the articulatory domain, and the mappings are estimated from simultaneous audio and EMA recordings. This offers the opportunity to enforce articulator continuity over time, and hence incorporate articulatory constraints into the recognizer. SegRec, our development of the Balthasar codebase, has implemented token passing and various pruning strategies that have enabled practical recognition experiments in this project, including triphones with multi-layer segmental HMMs.
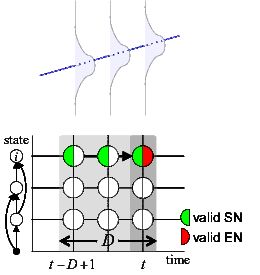
Fig. 4: Trellis of segmental probability calculation (lower) of duration D=3 (upper) from Start Node to End Node at t.
Identification of articulator constraints
In contrast to the descriptions of phonemes found on the International Phonetic Alphabet (IPA) chart, speech technologies need quantitative descriptions of typical phone characteristics in a voice, including effects of phoneme-to-phone mapping and ways to incorporate other sources of knowledge. IPA was designed to capture linguistic distinctions from human speech, observed by phoneticians. So, one of the motivations for our work, as engineers and speech scientists, is to attempt to bridge this gap, understanding the need for numerical values derived from a compact representation of the English phonetic repertory. Both as a means of validation and investigation, we compared articulator constraints derived from the IPA descriptions to those obtained with our algorithm.
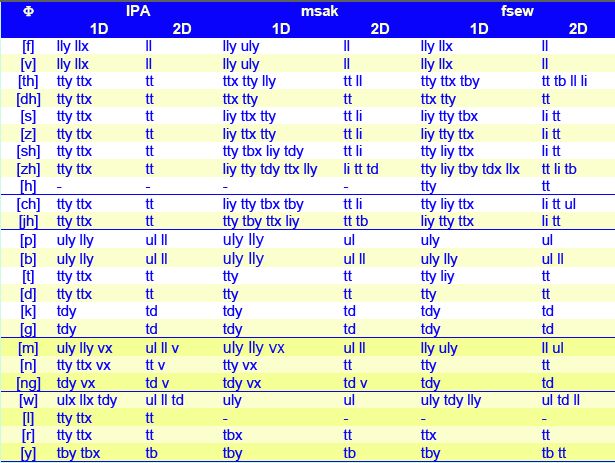
Table 1: Comparison for consonants of critical articulators expected from IPA chart descriptions (IPA), and identified by our algorithm from male (msak) and female (fsew) data. MOCHA-TIMIT phone and fleshpoint labels are used with 1D and 2D versions of the algorithm.
From the results for consonants, listed in Table 1, the main findings are:
- fricatives and affricates were most constrained, selecting the jaw LI as a critical articulator for [s,z,sh,zh,ch,jh], as well as the expected IPA place of articulation
- stops and nasals gave the expected place, after we corrected labels (see Mocha for details)
- velum was identified in nasals as secondary for one subject
- liquids and semivowels were similar to predictions, except for the lateral [l].
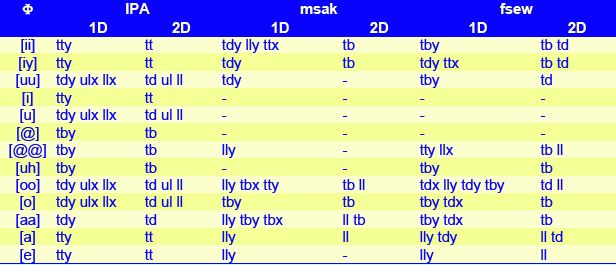
Table 2: Comparison for vowels of critical articulators expected from IPA chart descriptions (IPA), and identified by our algorithm from male (msak) and female (fsew) data. MOCHA-TIMIT phone and fleshpoint labels are used with 1D and 2D versions of the algorithm.
For vowels, whose targets are defined in both acoustic and articulatory domains, the main findings from Table 2 are:
- high front and back vowels selected TBy or TDy on the tongue
- central and reduced vowels picked no critical articulators
- open and low vowels tended to choose the lower lip LLy
- low back vowels also picked TBx or TBy on the blade of the tongue.
References
| [Wrench01] | A.A. Wrench. A new resource for production modelling in speech technology. In Proc. Inst. of Acoust. (WISP), Stratford-upon-Avon, UK, volume 23 (3), pages 207-217, 2001. |