EEM.ssr: Tutorial solutions
Week 1
Speech recognition:- Give a definition of automatic speech recognition that distinguishes it from other speech technologies.
ASR converts spoken words to text, whereas spoken language understanding includes machine reading comprehension, for example. - How can speech technologies be said to increase access of
people with disabilities to computer-based systems?
As a method for converting natural language from one modality (auditory) into another (visual), ASR can form part of a more flexible human-computer interface, especially for those with limited auditory function. Equally, speech synthesis (i.e., TTS) can help the blind or visually impaired access information stored on computer or the internet by vocalising text. Speech recognition can be used to assist those unable to type, e.g., through disability or injury, with text input. Speech synthesis can provide a voice where the user cannot speak. Sometimes providing an interface that combines modalities can be of benefit to people with learning difficulties or special needs of various descriptions.
Speech communication:
- What acronym denotes the convention for transcribing the sounds of
the world's languages?
IPA, International Phonetic Alphabet. - What is the difference between phones and phonemes?
A phoneme is an abstract sound category within a language, whereas a phone denotes a practical realisation by a given speaker in a particular context. - What three attributes of natural speech contribute most to the
non-linguistic aspects known as prosody?
(i) intensity or amplitude, (ii) timing or duration, and (iii) pitch or intonation.
Phonetics:
- How can a basic understanding of phonetics facilitate
the study of speech signals?
It informs us of the sounds of a language and their categorisation. - What is a diphthong? Illustrate your answer with an example.
A transition from one vowel sound to another, e.g., as in "by", "boy" and "bough". - What class of sounds includes /m/, /n/ and /ng/?
Nasals are all produced with an occlusion of the vocal tract in the oral cavity. - What characteristics of the acoustic signal are most useful for
discriminating vowels?
The first two formant frequencies, F1 and F2. - Give three environmental factors that can affect the way
speech is produced.
Noise (Lombard effect), vibration, stress/fear, cognitive loading, fatigue, gas properties (air pressure/helium), etc. - What are the three places of articulation for English plosive
consonants (aka. stops )?
Labial (at the lips), alveolar (at the palatal ridge toward the front of the mouth), and velar (on the soft palate further back in the mouth). - What is the main difference between the way that the sounds
/t/ and /s/ are produced?
/t/ is a plosive consonant which has a transient burst when air is suddenly released; /s/ is a fricative consonant which is produced by turbulent flow and can be sustained. However, they are both produced at approximately the same place of articulation. - What name is given to the effect in fluent speech where, for
example, the phrase ``isn't it'' is pronounced as if it were ``in'it''?
Elision, just like "bread and butter" becoming "brembudder".
Week 2
Dynamic Time Warping:
- Write a pseudocode description of the DTW algorithm using the
transitions shown in Fig.1 (left).
Apply a distortion penalty for the horizontal (H) and steepest (S) transitions,
dH = dS = dμ/4,
where dμ denotes the mean distance found across the
training data.
1. Initially: D(1,i) = { d(1,i)
{ 0for i=1
otherwise (2,...,N)2. For t=2,...,T: D(t,i) = { d(t,i) + D(t-1,i)+dH
{ d(t,i) + min[ D(t-1,i)+dH, D(t-1,i-1) ]
{ d(t,i) + min[ D(t-1,i)+dH, D(t-1,i-1), D(t-1,i-2)+dS ]for i=1
for i=2
otherwise (3,...,N)3. Finally: Δ = D(T,N)
- Modify your pseudocode to disallow two consecutive horizontal
transitions, as shown in Fig.1 (right).
1. Initially: D(1,i) = { d(1,i)
{ 0for i=1
otherwise (2,...,N)isFlat(i) = FALSE for i=1,...,N 2a. For t=2: D(t,i) = { d(t,i) + D(t-1,i)+dH
{ d(t,i) + min[ D(t-1,i)+dH, D(t-1,i-1) ]
{ d(t,i) + min[ D(t-1,i)+dH, D(t-1,i-1), D(t-1,i-2)+dS ]for i=1
for i=2
otherwise (3,...,N)isFlat(i) = { TRUE
{ FALSEif arg min == D(t-1,i)+dH
otherwisefor i=1,...,N 2b. For t=3,...,T: if isFlat(i) == TRUE D(t,i) = { INFINITY
{ d(t,i) + D(t-1,i-1)
{ d(t,i) + min[ D(t-1,i-1), D(t-1,i-2)+dS ]for i=1
for i=2
otherwise (3,...,N)isFlat(i) = FALSE for i=1,...,N else D(t,i) = { d(t,i) + D(t-1,i)+dH
{ d(t,i) + min[ D(t-1,i)+dH, D(t-1,i-1) ]
{ d(t,i) + min[ D(t-1,i)+dH, D(t-1,i-1), D(t-1,i-2)+dS ]for i=1
for i=2
otherwise (3,...,N)isFlat(i) = { TRUE
{ FALSEif arg min == D(t-1,i)+dH
otherwisefor i=1,...,N end 3. Finally: Δ = D(T,N)
- How can silence and wildcard templates be used during
enrollment to help reduce end-point detection errors?
These templates are introduced in (Holmes & Holmes, §8.10, p.123), and their use in training is duscussed in §8.13 on pp.125-6. In essence the silence template allows for gaps and pauses in a recording, and the wildcard can be used to represent parts of a training utterance that are being captured.
Speech production:
- What human organ produces quasi-periodic source of voiced sounds, such
as vowels?
Vocal folds (aka. vocal cords) which are in the larynx. - What is fundamental frequency (also called
f0), and how is it produced?
It is the frequency that separates the pitch harmonics in the spectrum and is usually the frequency of the lowest harmonic peak. The periodic vibration is the result of oscillation of the vocal folds, in the larynx. - The vocal tract comprises three main passages. The pharynx and
oral cavity are two. What is the third?
Nasal cavity. - The velum, larynx and jaw cooperate in the production of speech.
Name two other articulators.
Lips and tongue (body or tip). - What is a formant and how is it produced?
A frequency region of high amplitude in a speech spectrum or spectrogram which is produced as the result of an acoustic resonance in the vocal tract.
Speech analysis:
- What is the name of the organ in the inner ear that is responsible for
converting physical vibrations into a set of nerve responses
(i.e., electrical signals)?
Cochlea. - What is the bandwidth to which the human ear responds (to one significant
figure), and what are the implications?
20 kHz, which implies a sampling rate above 40 kHz for hi-fi quality. - If I calculate a DFT directly from a 40ms section of a speech signal, what
will be the spacing of frequency bins in the spectrum?
25 Hz. - Boxcar (rectangular), Kaiser and Blackman define certain kinds of window. Name
three other popular window functions.
Hann, Hamming, Bartlett (triangular), Tukey, Gaussian, etc. - What would be an appropriate window size for a narrow-band
spectrogram?
Choosing 40 Hz between adjacent bins implies a minimum 25 ms window, typically it is at least 30 ms. - Give an estimate of the SNR for a full-scale 16-bit speech signal
in relation to the quanisation noise.
Signal uses 216 peak-to-peak, the noise is 20=1 (+/- half a bit), which gives a range of 96 dB (=16×6 dB).
Week 3
Markov models:
P(X={1,1,3}|x1=1,M) = 0.12, P(X={1,2,3}|x1=1,M) = 0.06, P(X={1,3,3}|x1=1,M) = 0.24, Well, it looks like it's going to be sunny tomorrow too! |
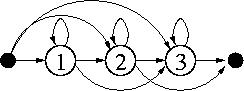
Fig.S1. State transitions. |
Hidden Markov models:
|
|
(a) 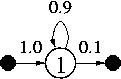 (b)
(b) 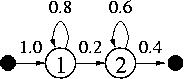
Fig.2. HMM state transitions. |
Feature extraction 1:
- How can a bank of band-pass filters (each tuned to a different centre
frequency) be used to extract a feature vector that describes the overall
spectral shape of an acoustic signal at any particular time?
A vector can be made up by taking the energy in each band, averaged over a short period (e.g., 20 ms). - The real cepstrum of a digital signal sampled at 48 kHz is defined
as cs(m) = IDFT( ln|S(k)| ), where S(k) is the signal's discrete
Fourier spectrum, ln|.| denotes the natural logarithm and IDFT is the inverse
discrete Fourier transform.
Considering only real, symmetric elements in the log-magnitude spectrum (i.e.,
the cos terms), draw the shapes of the first four cepstral coefficients
c0, c1, c2 and c3, in the
log-magnitude spectral domain.
These are respectively a constant and three cosine functions of the form cos x, cos 2x and cos 3x. - What properties of the Mel-frequency cepstrum make it more like human
auditory processing, compared to the real cepstrum?
The warping of the frequency axis, based on human pitch perception. - In calculating MFCCs, what is the purpose of:
- the log operation;
compression, source-filter decomposition - mel-frequency binning;
perceptual weighting of information - Discrete Cosine Transform?
make coefficients independent, diagonalising their covariance
- the log operation;
Week 4
Hidden Markov models:|
|
(a)
(b)
Fig.2. HMM state transitions. 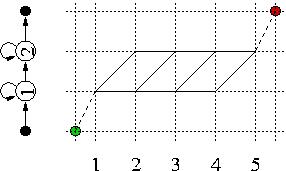
Fig.S2. Trellis diagram for τ=5. |
Week 5
HMM decoding:
- In the Viterbi algorithm, what is the purpose of the variable
ψt(i)?
Indicator of the best predecessor, which can then be used during traceback to identify the best path.
- What is the meaning of Δ*?
The total likelihood of the best path, the joint probability of the observations and the optimal state sequence given a particular model P(O,X*|λ).
- Using the Viterbi algorithm, calculate the path likelihoods
δt(i), the value of
Δ*, and use the values of
ψt(i) to extract the best path X*.
Model parameters:
π=[1 0], A=[0.8 0.2; 0.0 0.6],
η=[0 0.4]T, and B=[0.5 0.2 0.3; 0.0 0.9 0.1] where the
columns of the B matrix correspond to green (G), blue (B) and red (R) events,
respectively.
- for observations O¹={G,B,B} (worked example from lecture)
Step 1. δ1(1) = 1×0.5 = 0.5 ψ1(1) = 0 δ1(2) = 0 ψ1(2) = 0 Step 2. δ2(1) = 0.5×0.8×0.2 = 0.08 ψ2(1) = 1 δ2(2) = 0.5×0.2×0.9 = 0.09 ψ2(2) = 1 δ3(1) = 0.08×0.8×0.2 = 0.0128 ψ3(1) = 1 δ3(2) = max[0.08×0.2, 0.09×0.6] × 0.9
=0.054×0.9 = 0.0486ψ3(2) = 2 Step 3. Δ* = max[0.0128×0, 0.0486×0.4] = 0.01944 x3* = 2 Step 4. x2* = ψ3(x3*) = ψ3(2) = 2 x1* = ψ2(x2*) = ψ2(2) = 1 X*¹={1,2,2}
- for observations O²={R,B}
Step 1. δ1(1) = 1×0.3 = 0.3 ψ1(1) = 0 δ1(2) = 0 ψ1(2) = 0 Step 2. δ2(1) = 0.3×0.8×0.2 = 0.048 ψ2(1) = 1 δ2(2) = 0.3×0.2×0.9 = 0.054 ψ2(2) = 1 Step 3. Δ* = max[0.048×0, 0.054×0.4] = 0.0216 x2* = 2 Step 4. x1* = ψ2(x2*) = ψ2(2) = 1 X*²={1,2}
- for observations O¹={G,B,B} (worked example from lecture)
- What is the difference between the cumulative likelihoods
αt(i) computed in the forward procedure, and those
δt(i) computed in the Viterbi algorithm?
The probability αt(i)=P(o1t, xt=i|λ) is based on all possible paths leading to the current node; whereas δt(i)=P(o1t, x1t-1, xt=i|λ) is based only on the best path upto and including the current state i.
- Floating-point variables with double precision (i.e.,
4 bytes) can store values down to 1e-308, typical state-transition
probs are in the order of 0.1, and the multi-dimensional output probability
would be around 0.01 for a good match.
-
Given these approximations and assuming no re-scaling of the probabilities,
state at what stage would it become impossible to compare competing hypotheses
(i.e., different paths through the trellis)?
In other words, after how many observations would you expect the likelihoods to
suffer from numerical underflow?
So, we need to find the value of T for which (1e-3)T=1e-308.
T=log(1e-308)/log(1e-3) = 103, or ∼100 observations.
- With an observation frame rate of 10 ms, roughly how long would
this take?
1 second.
-
Given these approximations and assuming no re-scaling of the probabilities,
state at what stage would it become impossible to compare competing hypotheses
(i.e., different paths through the trellis)?
In other words, after how many observations would you expect the likelihoods to
suffer from numerical underflow?
- Instead of storing the likelihoods directly as in the previous
question, we choose to store them as negative log probabilities using a 16-bit
unsigned integer (quantising each decade into 32 levels).
- How many decades (factors of ten) can we represent with this data
type?
65536/32 = 2048 decades.
- How many seconds of observations (at 10 ms) could we now process
before suffering from underflow?
2048/(3×100) = 6.83 s, or ∼7 seconds.
- How many decades (factors of ten) can we represent with this data
type?