|
The features we use are based on the simple Haar basis features
used by Viola and Jones[3].
We have extended them into the temporal domain as shown in figure
2. We rely on the learning system to combine these basic features
in such a way as to depict the motion rather than choosing complex
classifiers to start with. Each feature returns a value which
is the difference between the values of the two volumes. Since
all of our features are rectangular volumes we can speed up the
calculations if we consider an interior and exterior box. The
value of the feature is then given by the summation of the pixels
in the blue box minus twice that of those in the red box.
|
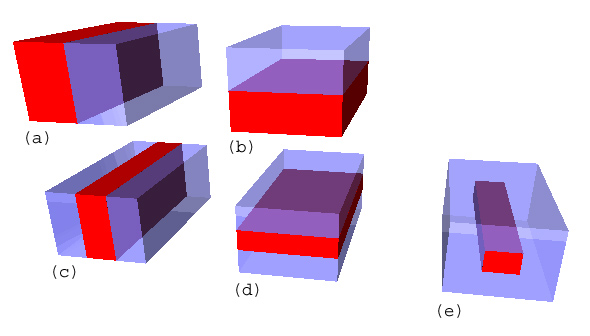 |
| figure 2 - Five of the seven features used are shown,
the two not shown are the inverses of (a) and (b) |
|