Large Lexicon Detection of Sign
By moving to the viseme level we can expand our sign vocabulary without extensively increasing the number of classifiers required. This work looks at viseme detection based on temporal moments and spatial features which are fed into a Markov chain for word level recognition. This is then compared to similar tests using visemes from accurately tracked data.
The following pages outline the two stage classification process:
Stage I - Viseme Detection - Grid : Using a grid system to localise the motion and learn TAB Visemes.
Stage I - Viseme Detection - Moments : Using moments to classify the motion and learn SIG and HA Visemes
Stage II - Word Level Learning : Combining the visemes into word level detection
Results : How this system compares with a similar perfectly tracked system
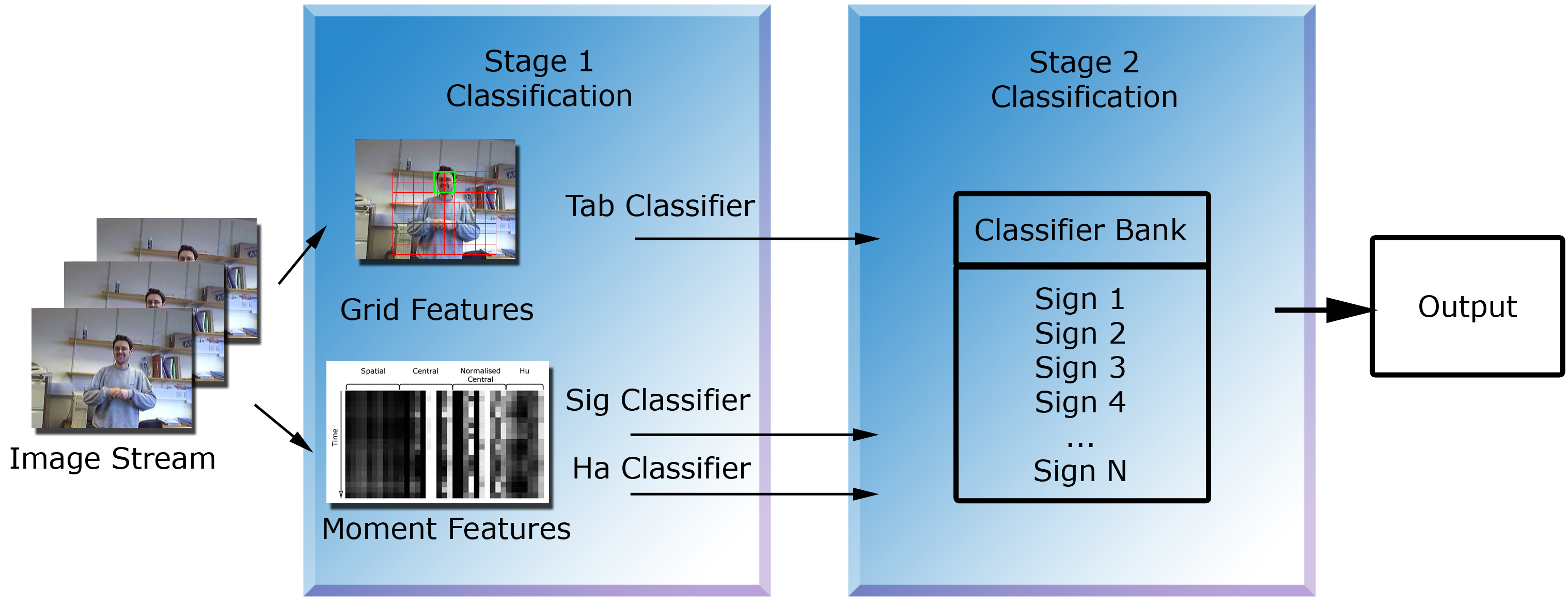
Figure 1 - Overview of the 2 stage classification process